
Comentarios sobre Slope One
Aug 21, 2016 · 2 minute read · Commentsrecsys
El objetivo del paper es mostrar que los algoritmos de Filtrado Colaborativo (CF) con Slope One pueden tener un performance similar a los clásicos algoritmos y además:
- Ser fáciles de implementar y mantener.
- Poder ser actualizados durante la ejecución.
- Ser rápidos en consultar.
La desventaja de los algoritmos que dependen de similaridades entre los usuarios es que hacen que el proceso sea lento y difícil de actualizar en tiempo real. En este sentido, Slope One tiene un esquema en base a modelos y no en memoria, lo que lo hace más eficiente en la práctica.
Si bien se afirma que Slope One es fácil de actualizar durante la ejecución, en particular la función de $ dev_{i,j} $, deja poco claro para personas no tan familiarizadas con el tema cuál sería la forma correcta de hacerlo. No tiene una implementación en psedo-código ni da pistas.
Otro punto importante es que cuando realiza la simplificación se asume que el dataset es denso. Esto en la práctica suele no ocurrir. Hubiera sido interesante tener benchmarks sobre un mismo dataset y comparar el método original versus el simplificado.
Una cosa que no me quedó claro (esto puede ser una mala interpretación mía), en la fórmula del Slope One con pesos, cuando se realiza la sumatoria, se excluye del arreglo de los ítems rateados del usuario el ítem que voy a predecir. Esto es como innecesario y redundante.
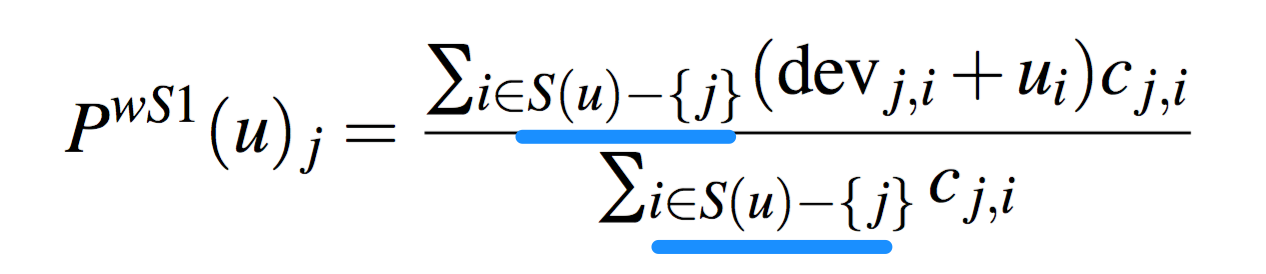
Finalmente, me parece muy interesante que la idea de separar los ítems que al usuario les gustó de los que no les gustó con BI-POLAR Slope One haya arrojado mayores resultados. Dando un toque desde una perspectiva de la psicología puede generar mejoras.